
type
status
date
slug
summary
tags
category
icon
password
如果把人工智能比做电脑的话,那大语言模型就是电脑的芯片。
在OpenAI的开发者大会上,OpenAI的创始人山姆有总结一组数据,2百万,92%,1亿,这三组数据分别代表了2百万的开发者,92%的世界500强企业和1亿的周活跃用户,由此可见现在人工智能的普及度。
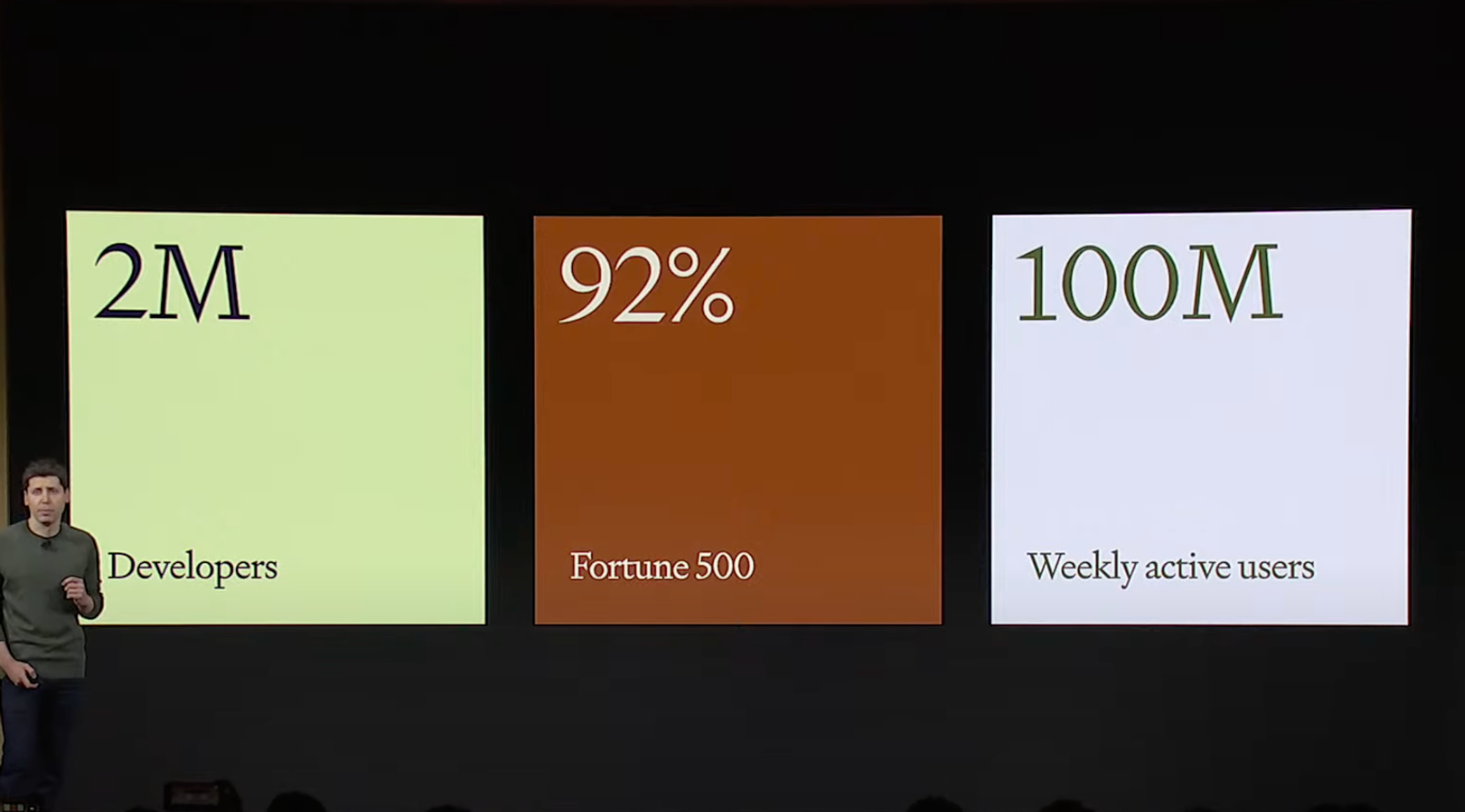
而大语言模型又是人工智能的核心,如何才能挑出合适的大模型呢,请看下文。
一、大语言模型的基础知识
在选择合适的大型模型之前,了解这些模型的基本原理和类型至关重要。
其中有几个比较关键的技术,我将深入浅出来科普一下。
- 神经网络架构:这是大模型的核心组成部分,如果把大模型比喻成人,那神经网络就是一个非常聪明的“大脑”,它通过学习大量的数据来理解世界。 就像我们通过经验学习识别不同的物体和语言一样,神经网络通过分析数据学习识别模式和关系。 卷积神经网络(CNN)擅长处理图像,递归神经网络(RNN)则擅长处理时间序列数据,比如文本或语音。
- 自然语言处理(NLP):NLP让计算机能够理解和回应人类语言,就像Siri或者Google Assistant一样。 它可以帮助计算机理解文本的含义,甚至模拟自然对话,用于客服聊天机器人或是自动翻译工具。
- Transformer架构:Transformer是一种先进的神经网络设计,特别擅长处理语言。它的核心是“自注意力机制”,这让网络不仅能关注单个词语,还能理解词与词之间的关系。 比如“他把球踢给了她”中的“他”和“她”。这种理解能力是翻译和文本生成中非常重要的。
- 预训练和微调:预训练就像给模型上一个基础课程,让它学习语言的基本规则。然后,通过微调,可以把这个“通才”模型专门训练成一个“专家”,比如专门处理法律文档或医疗记录。 微调这项技术能让开源的大模型部署在本地后,处理特定的某项任务时,能更加擅长。
- 大数据和计算要求:大型模型需要“读”很多数据来“学习”。这就像读很多书来增长知识一样。但因为需要处理的数据量非常大,所以这些模型需要强大的计算力,就像需要一个图书馆和一个快速的阅读者。 算力是大模型能成功的一个非常重要的先决条件,每一个面世的大模型都是经过了无数次训练的结果。
二、评估企业需求
虽然大语言模型的能力很强,但是还是得从企业的实际需求出发,是否能解决企业的问题。
每家企业的情况不同,根据应用场景,资源限制,安全和隐私,扩展性和可维护性等方面考量,具体可参考下表:
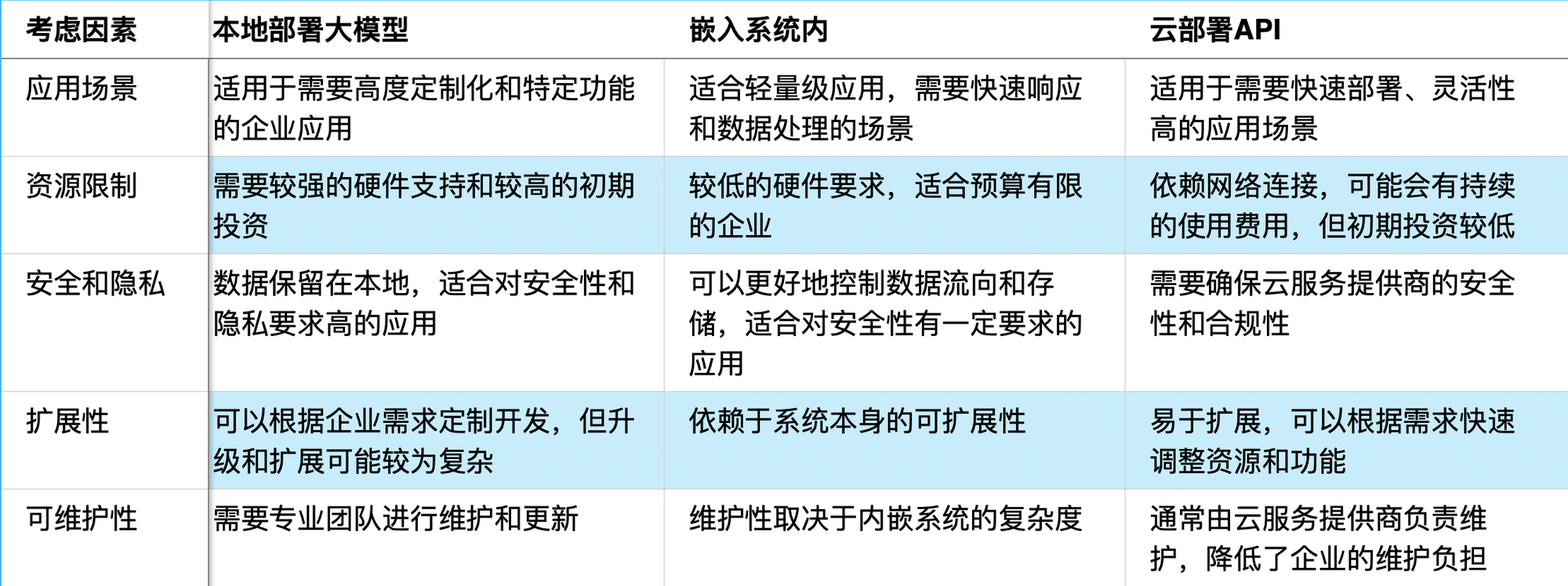
当然,上图只是给出了一些笼统的条件限制,真正到了实际应用的层面,还需要进行更深入的沟通才能配合好,可扫码加好友沟通。

三、比较不同的大语言模型
在比较各个大语言模型的过程中,我参考了国内外2个榜单的标准
- AI产品榜(国内):主要是以AI产品官网访问量为标准做排名。
- Huggingface(国外):开源AI公司,提供强大的自然语言处理工具和开源的预训练模型库。
在明确需求后,对比不同的大型模型成为必要步骤。这一过程涉及:
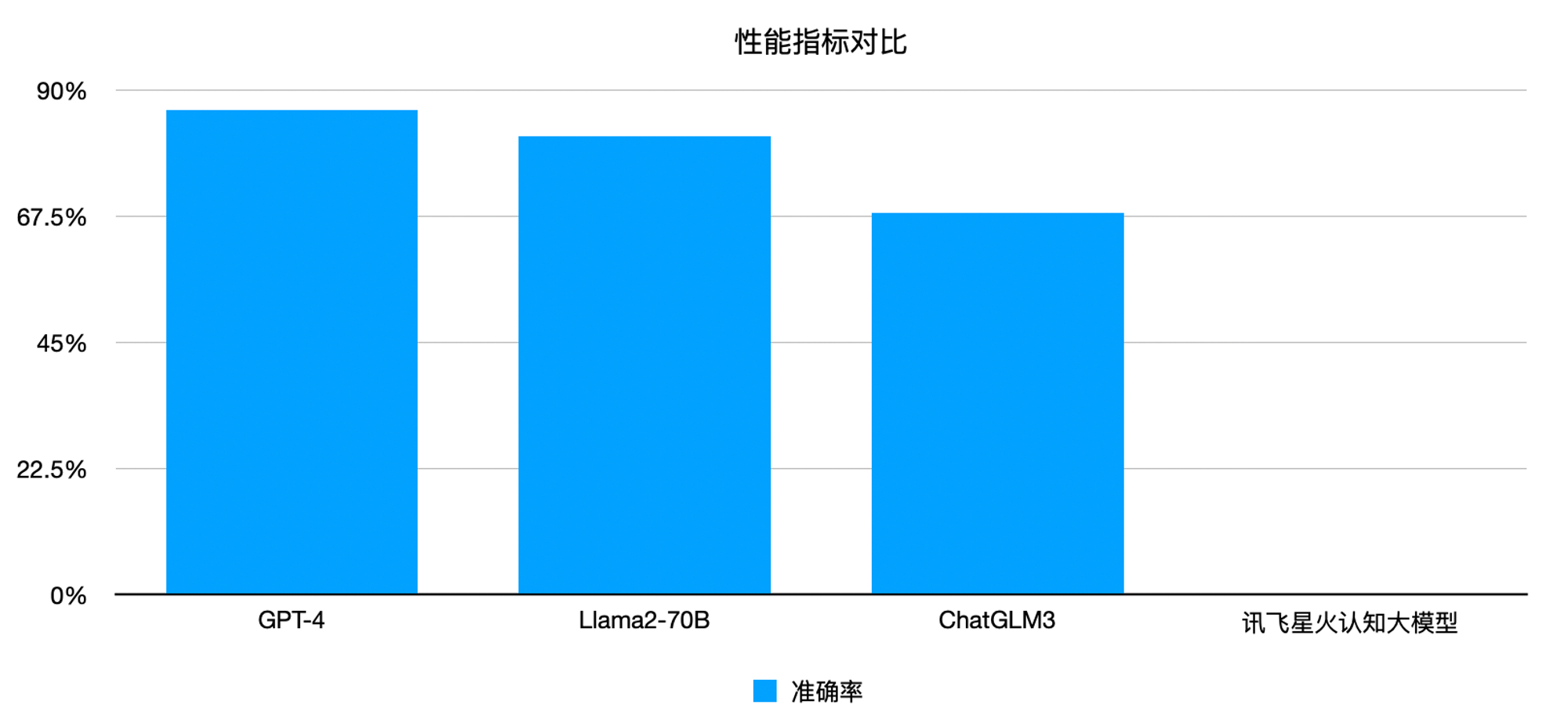
- 性能指标:查看各模型在标准测试中的表现,如准确率、响应时间等。
- 成本效益:评估部署和运行模型的总成本。
- 社区和支持:一个活跃的开发社区和强大的技术支持是成功部署模型的关键。
- 用户案例:研究其他企业使用模型的案例,以了解其在实际场景中的应用效果。
大语言模型我则选取GPT-4(OpenAI闭源),Llama2-70B(Meta开源),ChatGLM3(清华大学开源),讯飞星火认知大模型v3.0(科大讯飞闭源)
- 性能指标对比
- 成本效益 部署成本(本表格只考虑部署的费用,不考虑硬件,维护等其他费用):
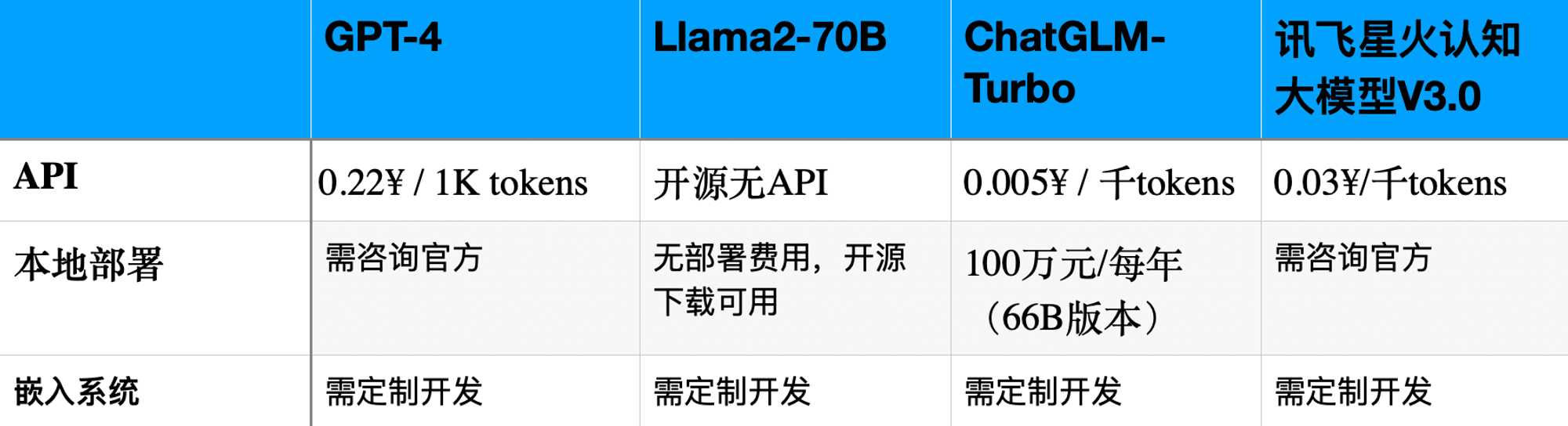
硬件成本:未涉猎到这个领域,需咨询相关专家,可参考以下几篇文章:
- 社区和支持 GPT-4的母公司OpenAI自然不用说,他们拥有全世界最优秀的AI开发人员和围绕OpenAI生态的2百万个开发者。

Llama2的母公司Meta,全球最大的社交应用Facebook的缔造者,同样拥有非常优秀的IT人才,不过在技术先发的情况下,Meta在生成式AI领域很难短时间内跟OpenAI抗衡。

ChatGLM3背靠清华大学,是一家2023年刚成立的新公司“智谱 AI”,开源了基础大语言模型,在国内同样是顶尖AI人才汇聚的公司,如今也正积极的进行商业运作。

讯飞星火认知大模型,在国内大模型中多个测评结果取得第一,背后的母公司科大讯飞是中国领先的人工智能(AI)技术公司之一,1999年就已经成立,一直专注于语音识别、自然语言处理、机器翻译、人机交互等领域的科技企业。

四、合规性
伦理和合规性是企业在选择和部署大型模型时不可忽视的重要方面。
2023年07月10日,国务院出台《生成式人工智能服务管理暂行办法》

这个文件的发行,意味着国内大语言模型如果要商用,必须通过备案。
所以在选择AI公司进行大语言模型部署时,需要考量对方是否已经备案,合法合规。
五、实施和优化
选择了合适的模型后,接下来是实施和优化。这包括:
- 集成到现有系统:确保模型能够与企业现有的IT架构无缝集成。
- 培训和调整:对团队进行必要的培训,并根据反馈对模型进行调整。
- 持续监控和评估:定期评估模型的性能和准确性,确保它能持续满足企业需求。
这一部分主要就是合作之后的一些后续细节,这也是需要考虑的点,后续的服务是否能跟上。
结语
选择和部署合适的大型模型是一项挑战,但也充满机遇。通过仔细评估需求、比较不同选项,并考虑伦理和合规性问题,企业可以充分利用大型模型带来的优势,推动业务发展。记住,选择大型模型不是一次性决策,而是一个持续的过程,需要随着业务的发展不断调整和优化。
- Author:何艺汇
- URL:https://github.com/murenren1/article/ba4490ea-e54e-426d-808f-6555cbb90cdf
- Copyright:All articles in this blog, except for special statements, adopt BY-NC-SA agreement. Please indicate the source!
Relate Posts
